Compositional Kernel Search for Gaussian Processes#
Despite its importance, choosing the right covariance kernel to use with a Gaussian Process model can be a difficult task. For example, when modelling long-term historical data, one may be interested in local seasonal effects (short-term periodic parts of the signal), as well as long-term global trends.
In addition to the commonly chosen kernel functions, the space of possible kernels become very complicated when including compositional kernels, such as adding or multiplying two kernels together. For a brief reference on compositional kernels, see here.
The twinlab library comes with a feature called Model Selection which automates the process of kernel selection and composition. This algorithm is a mix of two well-known algorithms: Compositional Kernel Search and Scalable Structure Discovery.
This notebook will cover:
Compositional Kernel Search in
Emulator
[1]:
# Third party imports
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
# twinlab import
import twinlab as tl
====== TwinLab Client Initialisation ======
Version : 2.0.0
Server : http://127.0.0.1:3000
Environment : /Users/jaspercantwell/Repos/twinLab-Demos/.env
Problem Formulation#
Here, we will design a function with multiple components that may be interest for modelling purposes.
[2]:
# The true function
def oscillator(x):
return np.cos((x - 5) / 2) * np.sin(10 * x / 5) + x * 0.2
X = np.linspace(-15, 15, 100)[:, np.newaxis]
y = oscillator(X) # Arrange outputs as feature columns
n_data = 200
X_data = np.random.uniform(-10, 10, size=n_data)
y_data = oscillator(X_data)
plt.plot(X, y)
plt.scatter(X_data, y_data)
plt.show()
[3]:
# Convert to dataframe
df = pd.DataFrame({"x": X_data, "y": y_data})
df.head()
[3]:
| x | y | |
|---|---|---|
| 0 | 8.711218 | 2.020326 |
| 1 | 9.924567 | 1.330421 |
| 2 | -6.551718 | -1.757520 |
| 3 | -0.507827 | 0.685194 |
| 4 | -9.283974 | -1.675230 |
[4]:
# Define the name of the dataset
dataset_id = "ModelSelect_Data"
# Initialise a Dataset object
dataset = tl.Dataset(id=dataset_id)
# Upload the dataset to the cloud
dataset.upload(df, verbose=True)
Dataframe is uploading.
Processing dataset
Dataset ModelSelect_Data was processed.
GP without Model Selection#
For a fair comparison, we will want to run a standard GP with the ubiquitous Matern 5/2 kernel first.
[5]:
# Initialise emulator
emulator_id = "BasicGP"
emulator = tl.Emulator(id=emulator_id)
# Define the training parameters for your emulator
params = tl.TrainParams(
train_test_ratio=0.75, estimator="gaussian_process_regression"
)
# Train the mulator using the train method
emulator.train(
dataset=dataset, inputs=["x"], outputs=["y"], params=params, verbose=True
)
Model BasicGP has begun training.
Training complete!
[6]:
# Plot inference results
df_pred = emulator.predict(pd.DataFrame(X, columns=["x"]))
result_df = pd.concat([df_pred[0], df_pred[1]], axis=1)
df_mean, df_stdev = result_df.iloc[:, 0], result_df.iloc[:, 1]
y_mean, y_stdev = df_mean.values, df_stdev.values
plt.fill_between(
X.flatten(),
(y_mean - 1.96 * y_stdev).flatten(),
(y_mean + 1.96 * y_stdev).flatten(),
color="k",
alpha=0.1,
)
plt.scatter(df["x"], df["y"], alpha=0.5, label="Training Data")
plt.xlabel("x")
plt.ylabel("y")
plt.plot(X, y, c="r", linewidth=2, label="True Function")
plt.plot(X, y_mean, c="k", linewidth=2, linestyle="dashed", label="Prediction")
plt.legend()
plt.show()
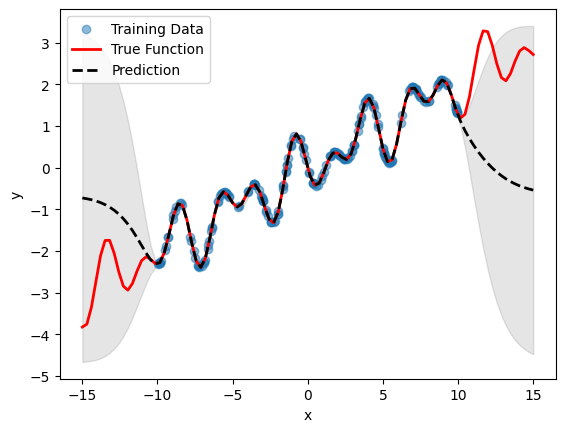
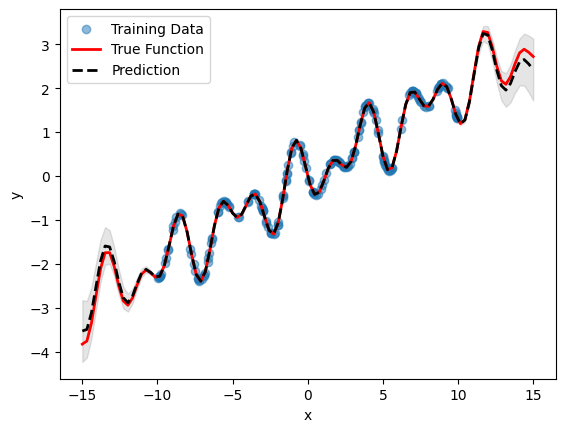
GP with Model Selection#
Model selection in twinlab is exposed via the 'model_selection'=True parameter in the TrainParams object. Additional parameters to control the model selection process can be passed to the 'model_selection_params' parameter which accepts an instantiation of the ModelSelectionParams object.
ModelSelectionParams object contains all the parameters required for the model selection process. This includes 'depth', which controls the maximum number of compositional kernels to search for, and 'beam', which controls the number of successful trials carried between search iterations. 'beam'=1 corresponds to greedy search, and 'beam'=None corresponds to grid search (this is the default, but will result in exponential computational complexity). It is highly recommended to
also provide a 'seed' keyword parameter to allow reproducibility.
Note that the model achieved by this process is no more correct when compared to the basic model (as they are just different ways of describing the same data), however the model with automatic compositional kernel may have better extrapolation properties.
[7]:
# Initialise emulator
emulator_id = "ModelSelectionGP"
model_selection_emulator = tl.Emulator(id=emulator_id)
# Define the model selction parameters
model_selection_params = tl.ModelSelectionParams(depth=4, beam=2, seed=123)
# Define the training parameters for your emulator
new_params = tl.TrainParams(
model_selection=True,
model_selection_params=model_selection_params,
train_test_ratio=0.75,
estimator="gaussian_process_regression",
)
# Train the mulator using the train method
model_selection_emulator.train(
dataset=dataset, inputs=["x"], outputs=["y"], params=new_params, verbose=True
)
Model ModelSelectionGP has begun training.
Training complete!
[8]:
# Plot inference results
df_pred = model_selection_emulator.predict(pd.DataFrame(X, columns=["x"]))
result_df = pd.concat([df_pred[0], df_pred[1]], axis=1)
df_mean, df_stdev = result_df.iloc[:, 0], result_df.iloc[:, 1]
y_mean, y_stdev = df_mean.values, df_stdev.values
plt.fill_between(
X.flatten(),
(y_mean - 1.96 * y_stdev).flatten(),
(y_mean + 1.96 * y_stdev).flatten(),
color="k",
alpha=0.1,
)
plt.scatter(df["x"], df["y"], alpha=0.5, label="Training Data")
plt.xlabel("x")
plt.ylabel("y")
plt.plot(X, y, c="r", linewidth=2, label="True Function")
plt.plot(X, y_mean, c="k", linewidth=2, linestyle="dashed", label="Prediction")
plt.legend()
plt.show()
[9]:
# Delete emulators and dataset
emulator.delete()
model_selection_emulator.delete()
dataset.delete()