Introduction#
This guide follows the same format as quickstart but explores further functionality provided by twinLab. In this jupyter notebook we will:
Upload a dataset to twinLab.
List, view and summarise uploaded datasets.
Use
Emulator.trainto create a surrogate model.List, view and summarise trained emulators.
Use the model to make a prediction with
Emulator.predict.Visualise the results and their uncertainty.
Verify the model using
Emulator.sample.
[1]:
# Standard imports
from pprint import pprint
# Third-party imports
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
# Project imports
import twinlab as tl
====== TwinLab Client Initialisation ======
Version : 2.0.0
Server : https://twinlab.digilab.co.uk
Environment : /Users/mead/digiLab/twinLab-Demos/.env
Your twinLab information#
Confirm your twinLab version
[2]:
tl.versions()
[2]:
{'cloud': '2.0.0',
'modal': '0.2.0',
'library': '1.3.0',
'image': 'twinlab-prod'}
And view your user information, including how many credits you have.
[3]:
tl.user_information()
[3]:
{'username': 'alexander', 'credits': 1000}
Upload a dataset#
Datasets must be data presented as a pandas.DataFrame object, or a filepaths which points to a csv file that can be parsed to a pandas.DataFrame object. Both must be formatted with clearly labelled columns. Here, we will label the input (predictor) variable x and the output variable y. In twinlab, data is expected to be in column-feature format, meaning each row represents a single data sample, and each column represents a data feature.
twinLab contains a Dataset class with attirbutes and methods to process, view and summarise the dataset. Datasets must be created with a dataset_id which is used to access them. The dataset can be uploaded using the upload method.
[4]:
x = [
0.6964691855978616,
0.28613933495037946,
0.2268514535642031,
0.5513147690828912,
0.7194689697855631,
0.42310646012446096,
0.9807641983846155,
0.6848297385848633,
0.48093190148436094,
0.3921175181941505,
]
y = [
-0.8173739564129022,
0.8876561174050408,
0.921552660721474,
-0.3263338765412979,
-0.8325176123242133,
0.4006686354731812,
-0.16496626502368078,
-0.9607643657025954,
0.3401149876855609,
0.8457949914442409,
]
# Creating the dataframe using the above arrays
df = pd.DataFrame({"x": x, "y": y})
# View the dataset before uploading
display(df)
# Define the name of the dataset
dataset_id = "example_data"
# Intialise a Dataset object
dataset = tl.Dataset(id=dataset_id)
# Upload the dataset
dataset.upload(df, verbose=True)
| x | y | |
|---|---|---|
| 0 | 0.696469 | -0.817374 |
| 1 | 0.286139 | 0.887656 |
| 2 | 0.226851 | 0.921553 |
| 3 | 0.551315 | -0.326334 |
| 4 | 0.719469 | -0.832518 |
| 5 | 0.423106 | 0.400669 |
| 6 | 0.980764 | -0.164966 |
| 7 | 0.684830 | -0.960764 |
| 8 | 0.480932 | 0.340115 |
| 9 | 0.392118 | 0.845795 |
Dataframe is uploading.
Processing dataset
Dataset example_data was processed.
View datasets#
Once a dataset has been uploaded it can be easily accessed using built in twinLab functions. A list of all uploaded datasets can be produced, individual datasets can be viewed and summarised. This summary contains some basic statistics of the data.
[5]:
# List all datasets on cloud
tl.list_datasets()
[5]:
['2DActive_Data',
'Excel-test',
'Falmouth-Mikey',
'New_Points',
'biscuits',
'eval_data',
'example_data',
'functional-data',
'functional-test-data',
'fusion',
'sampled-data',
'twinLab-logo']
[6]:
# View the dataset
dataset.view()
[6]:
| x | y | |
|---|---|---|
| 0 | 0.696469 | -0.817374 |
| 1 | 0.286139 | 0.887656 |
| 2 | 0.226851 | 0.921553 |
| 3 | 0.551315 | -0.326334 |
| 4 | 0.719469 | -0.832518 |
| 5 | 0.423106 | 0.400669 |
| 6 | 0.980764 | -0.164966 |
| 7 | 0.684830 | -0.960764 |
| 8 | 0.480932 | 0.340115 |
| 9 | 0.392118 | 0.845795 |
[7]:
# Get a statistical summary of the dataset
dataset.summarise()
[7]:
| x | y | |
|---|---|---|
| count | 10.000000 | 10.000000 |
| mean | 0.544199 | 0.029383 |
| std | 0.229352 | 0.748191 |
| min | 0.226851 | -0.960764 |
| 25% | 0.399865 | -0.694614 |
| 50% | 0.516123 | 0.087574 |
| 75% | 0.693559 | 0.734513 |
| max | 0.980764 | 0.921553 |
Train an emulator#
The Emulator class is used to train and implement your surrogate models. As with datasets, an id is defined, this is what the model will be saved as in the cloud. When training a model the arguments are passed using a TrainParams object; TrainParams is a class that contains all the necessary parameters needed to train your model. To train the model we use the Emulator.train function, inputting the TrainParams object as an argument to this function.
[8]:
# Initialise emulator
emulator_id = "example_emulator"
emulator = tl.Emulator(id=emulator_id)
# Define the training parameters for your emulator
params = tl.TrainParams(train_test_ratio=1.0)
# Train the mulator using the train method
emulator.train(dataset=dataset, inputs=["x"], outputs=["y"], params=params, verbose=True)
Model example_emulator has begun training.
Training complete!
View emulators#
Just as with datasets all saved emulators can be listed, viewed and summarised.
[9]:
# List emulators
tl.list_emulators()
[9]:
['2DActiveGP',
'Example_emulator',
'Excel-emulator',
'Excel-model',
'Hello',
'backward-model',
'biscuits',
'campaign',
'decoder',
'example_emulator',
'fusion',
'gardening',
'my_emulator',
'new-campaign',
'twinLab-logo',
'universe']
[10]:
# View an emulator's parameters
emulator.view()
[10]:
{'model_id': 'example_emulator',
'fidelity': None,
'estimator': 'gaussian_process_regression',
'estimator_kwargs': {'detrend': False,
'device': 'cpu',
'covar_module': None,
'estimator_type': None},
'decompose_input': False,
'input_explained_variance': 0.99,
'decompose_output': False,
'output_explained_variance': 0.99,
'train_test_ratio': 1.0,
'model_selection': False,
'model_selection_kwargs': {'seed': None,
'evaluation_metric': 'MSLL',
'val_ratio': 0.2,
'base_kernels': 'restricted',
'depth': 1,
'beam': None,
'resource_per_trial': {'cpu': 1, 'gpu': 0}},
'seed': None,
'inputs': ['x'],
'outputs': ['y'],
'dataset_id': 'example_data',
'modal_handle': 'fc-ktRp3Nc749lshsKZvgJH4y'}
[11]:
# View the status of a campaign
pprint(emulator.summarise())
{'model_summary': {'data_diagnostics': {'inputs': {'x': {'25%': 0.39986475367672814,
'50%': 0.5161233352836261,
'75%': 0.693559323844612,
'count': 10.0,
'max': 0.9807641983846156,
'mean': 0.544199352975335,
'min': 0.2268514535642031,
'std': 0.22935216613691597}},
'outputs': {'y': {'25%': -0.6946139364450011,
'50%': 0.0875743613309401,
'75%': 0.7345134024514759,
'count': 10.0,
'max': 0.921552660721474,
'mean': 0.029383131672480845,
'min': -0.9607643657025954,
'std': 0.7481906564998719}}},
'estimator_diagnostics': {'covar_module': 'ScaleKernel(\n'
' (base_kernel): '
'MaternKernel(\n'
' '
'(lengthscale_prior): '
'GammaPrior()\n'
' '
'(raw_lengthscale_constraint): '
'Positive()\n'
' )\n'
' '
'(outputscale_prior): '
'GammaPrior()\n'
' '
'(raw_outputscale_constraint): '
'Positive()\n'
')',
'covar_module.base_kernel.lengthscale_prior.concentration': 3.0,
'covar_module.base_kernel.lengthscale_prior.rate': 6.0,
'covar_module.base_kernel.original_lengthscale': [[0.4232063885665337]],
'covar_module.base_kernel.raw_lengthscale': [[-0.6408405631160488]],
'covar_module.base_kernel.raw_lengthscale_constraint.lower_bound': 0.0,
'covar_module.base_kernel.raw_lengthscale_constraint.upper_bound': inf,
'covar_module.original_outputscale': 1.7130960752713094,
'covar_module.outputscale_prior.concentration': 2.0,
'covar_module.outputscale_prior.rate': 0.15000000596046448,
'covar_module.raw_outputscale': 1.514271061131159,
'covar_module.raw_outputscale_constraint.lower_bound': 0.0,
'covar_module.raw_outputscale_constraint.upper_bound': inf,
'input_transform._coefficient': [[0.7539127448204125]],
'input_transform._offset': [[0.2268514535642031]],
'likelihood.noise_covar.noise_prior.concentration': 1.100000023841858,
'likelihood.noise_covar.noise_prior.rate': 0.05000000074505806,
'likelihood.noise_covar.original_noise': [0.031576525703137535],
'likelihood.noise_covar.raw_noise': [0.031576525703137535],
'likelihood.noise_covar.raw_noise_constraint.lower_bound': 9.999999747378752e-05,
'likelihood.noise_covar.raw_noise_constraint.upper_bound': inf,
'mean_module': 'ConstantMean()',
'mean_module.original_constant': 0.21052500685316855,
'mean_module.raw_constant': 0.21052500685316855,
'outcome_transform._stdvs_sq': [[0.5597892584737093]],
'outcome_transform.means': [[0.029383131672480856]],
'outcome_transform.stdvs': [[0.7481906564998719]]},
'transformer_diagnostics': []}}
Prediction using the trained emulators#
The surrogate model is now trained and saved to the cloud under the emulator_id. It can now be used to make predictions. First define a dataset of inputs for which you want to find outputs; ensure that this is a pandas.DataFrame object. Then call Emulator.predict with the keyword arguments being the evaluation dataset.
[12]:
# Define the inputs for the dataset
x_eval = np.linspace(0, 1, 128)
# Convert to a dataframe
df_eval = pd.DataFrame({"x": x_eval})
display(df_eval)
# Predict the results
predictions = emulator.predict(df_eval)
result_df = pd.concat([predictions[0], predictions[1]], axis=1)
df_mean, df_stdev = result_df.iloc[:,0], result_df.iloc[:,1]
df_mean, df_stdev = df_mean.values, df_stdev.values
print(result_df.head())
| x | |
|---|---|
| 0 | 0.000000 |
| 1 | 0.007874 |
| 2 | 0.015748 |
| 3 | 0.023622 |
| 4 | 0.031496 |
| ... | ... |
| 123 | 0.968504 |
| 124 | 0.976378 |
| 125 | 0.984252 |
| 126 | 0.992126 |
| 127 | 1.000000 |
128 rows × 1 columns
y y
0 0.617689 0.656265
1 0.629105 0.640576
2 0.640630 0.624421
3 0.652252 0.607809
4 0.663957 0.590755
Viewing the results#
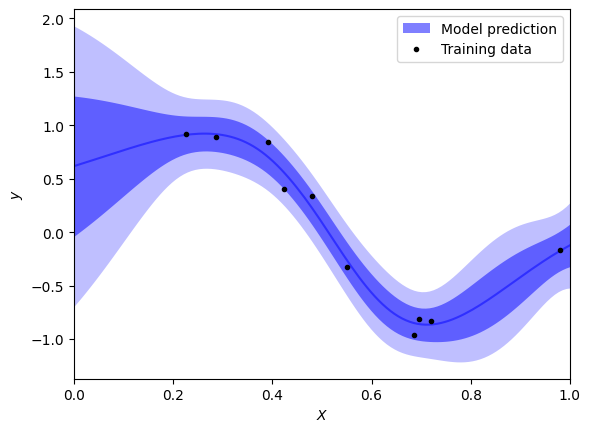
Emulator.predict outputs mean values for each input and their standard deviation; this gives the abilty to nicely visualise the uncertainty in results.
[13]:
# Plot parameters
nsigs = [1, 2]
color = "blue"
alpha = 0.5
plot_training_data = True
plot_model_mean = True
plot_model_bands = True
# Plot results
grid = df_eval["x"]
mean = df_mean
err = df_stdev
if plot_model_bands:
label = r"Model prediction"
plt.fill_between(grid, np.nan, np.nan, lw=0, color=color, alpha=alpha, label=label)
for isig, nsig in enumerate(nsigs):
plt.fill_between(
grid,
mean - nsig * err,
mean + nsig * err,
lw=0,
color=color,
alpha=alpha / (isig + 1),
)
if plot_model_mean:
label = r"Model prediction" if not plot_model_bands else None
plt.plot(grid, mean, color=color, alpha=alpha, label=label)
if plot_training_data:
plt.plot(df["x"], df["y"], ".", color="black", label="Training data")
plt.xlim((0.0, 1.0))
plt.xlabel(r"$X$")
plt.ylabel(r"$y$")
plt.legend()
plt.show()
Sampling from an emulator#
The Emulator.sample function can be used to retrieve a number of results from your model. It requires the inputs for which you want the values and how many outputs to calculate for each.
[14]:
# Define the sample inputs
sample_inputs = pd.DataFrame({"x": np.linspace(0, 1, 128)})
# Define number of samples to calculate for each input
num_samples = 100
# Calculate the samples using twinLab
sample_result = emulator.sample(sample_inputs, num_samples)
# View the results in the form of a dataframe
display(sample_result)
| y | |||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | ... | 90 | 91 | 92 | 93 | 94 | 95 | 96 | 97 | 98 | 99 | |
| 0 | 1.264127 | 1.259498 | 0.664856 | 1.290327 | -1.061115 | 0.063356 | 1.326666 | 1.789418 | -0.009024 | 1.259869 | ... | 0.939294 | 0.362207 | 0.011521 | 1.053759 | -0.409518 | 1.014478 | 0.751929 | 1.641282 | 0.826082 | 0.469116 |
| 1 | 1.263028 | 1.274143 | 0.643489 | 1.300232 | -0.994251 | 0.108671 | 1.342242 | 1.764897 | 0.008574 | 1.246439 | ... | 0.978143 | 0.343955 | 0.050809 | 1.024005 | -0.418823 | 1.016179 | 0.779650 | 1.598208 | 0.826613 | 0.468406 |
| 2 | 1.260150 | 1.283785 | 0.621806 | 1.308611 | -0.921023 | 0.157252 | 1.354430 | 1.740139 | 0.031373 | 1.232385 | ... | 1.014755 | 0.328073 | 0.091420 | 0.993893 | -0.423898 | 1.014795 | 0.809190 | 1.552288 | 0.830950 | 0.468252 |
| 3 | 1.256019 | 1.290381 | 0.602094 | 1.315111 | -0.842858 | 0.207179 | 1.363444 | 1.714233 | 0.056631 | 1.218001 | ... | 1.048197 | 0.315876 | 0.130009 | 0.965887 | -0.424134 | 1.010628 | 0.840416 | 1.503579 | 0.839256 | 0.469101 |
| 4 | 1.249843 | 1.294567 | 0.584412 | 1.319314 | -0.762038 | 0.258642 | 1.367987 | 1.686284 | 0.081911 | 1.204734 | ... | 1.077572 | 0.307563 | 0.166610 | 0.942370 | -0.419536 | 1.003131 | 0.871847 | 1.452200 | 0.851765 | 0.470634 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 123 | -0.243466 | -0.376759 | -0.222920 | -0.164613 | -0.123029 | -0.107526 | -0.491095 | -0.200305 | -0.075683 | -0.080205 | ... | -0.130376 | -0.088158 | 0.005756 | -0.193393 | -0.067758 | -0.131498 | -0.122326 | -0.211535 | -0.343941 | -0.117467 |
| 124 | -0.237385 | -0.361383 | -0.176733 | -0.150867 | -0.107936 | -0.042114 | -0.411948 | -0.214185 | -0.082167 | -0.053210 | ... | -0.099505 | -0.143001 | -0.020947 | -0.184918 | -0.064551 | -0.152278 | -0.089314 | -0.181028 | -0.336784 | -0.087687 |
| 125 | -0.229653 | -0.344955 | -0.129858 | -0.138228 | -0.093384 | 0.024250 | -0.334807 | -0.228415 | -0.090190 | -0.028539 | ... | -0.063867 | -0.199541 | -0.047168 | -0.171532 | -0.062122 | -0.173057 | -0.057060 | -0.150006 | -0.333920 | -0.053370 |
| 126 | -0.220961 | -0.326984 | -0.082629 | -0.126160 | -0.080773 | 0.088925 | -0.260510 | -0.242954 | -0.099340 | -0.005383 | ... | -0.024045 | -0.256805 | -0.072422 | -0.153905 | -0.059526 | -0.193384 | -0.026572 | -0.118515 | -0.335199 | -0.014476 |
| 127 | -0.211589 | -0.307667 | -0.034203 | -0.113222 | -0.070149 | 0.152874 | -0.191118 | -0.259736 | -0.108993 | 0.016120 | ... | 0.019210 | -0.314823 | -0.096437 | -0.133574 | -0.056565 | -0.213358 | 0.001427 | -0.087783 | -0.339115 | 0.027192 |
128 rows × 100 columns
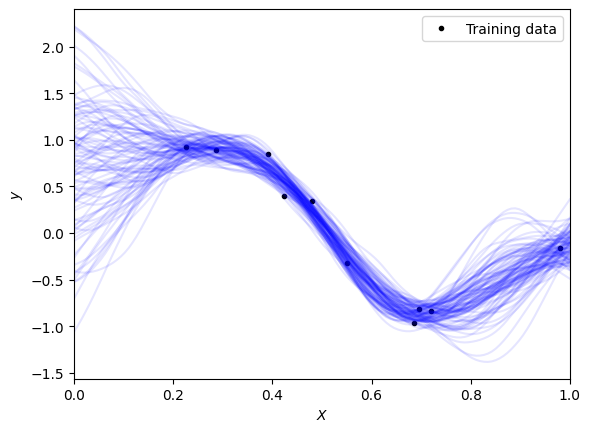
Viewing the results#
The results can be plotted over the top of the previous graph giving a nice visualisation of the sampled data, with the model’s uncertainity.
[15]:
# Plot parameters
color_curve = "blue"
alpha_curve = 0.10
color_data = "black"
plot_training_data = True
plot_model_bands = False
# Plot samples drawn from the model
if plot_training_data:
plt.plot(df["x"], df["y"], ".", color=color_data, label="Training data")
plt.plot(sample_inputs, sample_result["y"], color=color_curve, alpha=alpha_curve)
plt.xlim((0.0, 1.0))
plt.xlabel(r"$X$")
plt.ylabel(r"$y$")
plt.legend()
plt.show()
Deleting datasets and emulators#
To keep your cloud storage tidy you should delete your datasets and emulators when you are finished with them. Emulator.delete and Dataset.delete deletes the emulators and the datasets from the cloud storage respectively.
[16]:
# Delete dataset
dataset.delete()
# Delete emulator
emulator.delete()